Your cart is currently empty!
Дубли контента на сайте: причины и решения

Поисковая оптимизация подразумевает целый ряд обязательных мероприятий по устранению ошибок на продвигаемом сайте. Один из таких шагов – выявление и устранение дублирующегося контента. На удивление, практически ни один сайт не обходится без дублей. Причин тому множество, но на каждую из них можно найти адекватное решение. Виктор Гуменюк, Team Lead отдела продвижения сайтов SEO-Studio, рассказывает о дублях контента.

Что такое дублированный контент и откуда он берется
Казалось бы, каждый материал на сайте размещался строго в единственном экземпляре и лишним копиям взяться просто не откуда. На самом деле механизм появления дублей не так очевиден и здесь есть куда «копнуть».
Одной странице – один уникальный URL-адрес. Справедливость такого требования подтверждает сама интуиция, ведь вполне естественно, что веб-страница не может находиться в разных местах одновременно (по разным URL-адресам). Но если на заре становления интернета это требование еще соблюдалось, то с появлением динамических сайтов и продвинутых систем управления контентом (CMS) оказалось, что любая страница может быть доступна по бесчисленному количеству URL-адресов одновременно. Именно это и создает проблемы.
Когда поисковая система находит несколько URL-адресов, которые ведут на один и тот же контент, возникает дилемма. Считать ли эти адреса одной страницей или разными? Особенно, если контент все-таки немного отличается, например, вспомогательными информационными блоками. И если нужно эти страницы «склеить», то какой URL считать основным?
Типичные ситуации
Существует множество ситуаций, которые приводят к появлению дублирующегося контента. Рассмотрим самые распространенные из них, которые можно назвать типичными.
- Добавление материала в разные категории. Если используется так называемый «человеко-понятный URL», в котором зафиксирована категория материала, система управления контентом сгенерирует несколько URL’ов, по одному для каждой из категорий. В результате появится более одной ссылки на один и тот же материал (такая проблема встречается уже довольно редко);
- Отдельная страница для печати. Страница для печати отличается от основной страницы только стилями оформления. Но главное здесь, что отличия все-таки имеются, и поисковая система должна будет выбрать URL для индексации и отображения в поисковой выдаче на свое усмотрение (такая проблема тоже встречается редко);
- Идентификаторы сеансов. Для того чтобы отслеживать посетителей на сайте зачастую используются параметры в ссылке, которые могут содержать множество полезной информации. Это приводит к тому, что система генерирует множество уникальных ссылок на одни и те же страницы. Если посетитель оставит где-нибудь ссылку со своим идентификатором сеанса, поисковая система эту ссылку найдет и тем самым обнаружит еще один лишний дубль;
- Параметры сортировки. Для отслеживания параметров сортировки нередко используют тот же URL. Как и в предыдущем примере, это приводит к созданию дублей. Например, товары могут быть отсортированы по алфавиту, по дате добавления или по цене. Учитывая URL без параметров (сортировка по умолчанию), возникает уже 4 ссылки на одну и ту же страницу;
- Пагинация для комментариев. Некоторые CMS используют пагинацию для комментариев, чтобы разбить их на несколько страниц. При переходе на другую страницу, основной контент будет сохраняться тем же, но в ссылке появится дополнительный параметр. Причем этот параметр будет уникальным для каждой страницы. Соответственно каждая такая страница вполне справедливо может восприниматься как дубликат основного контента с незначительными изменениями в комментариях;
- Домен с и без www. Типичная ситуация, когда домен доступен в двух вариантах сразу – с приставкой «www» и без нее. В последнее время появилась вариация этой проблемы, связанная с переходом на новый протокол. Страницы могут быть доступны в одно и то же время по протоколу «http» и «https»;
- Произвольный порядок параметров. Если сайт не использует человеко-понятные URL’ы, ссылки на страницы генерируются в виде набора параметров «ключ=значение». При этом данные параметры можно произвольно менять местами, что приводит к созданию лишних дублей.
Как проверить сайт на дубли
Хороший способ проверить сайт на наличие дублей, использовать консоль для веб-мастеров Google. После входа в систему, нужно сначала открыть раздел «Вид в поиске», а затем – «Оптимизация HTML». Здесь можно увидеть исчерпывающий список дубликатов, найденных на сайте. Разумеется, для того чтобы воспользоваться этим инструментом, понадобиться учетная запись Google и подтверждение прав на сайт, который предполагается исследовать.
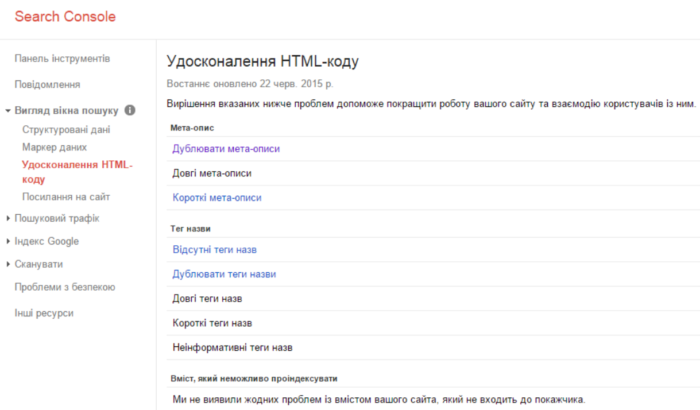
Но если вы только готовите сайт и он закрыт от индексации, с помощью консоли для веб-мастеров Google вы не сможете найти дубли. Мы в SEO-Studio используем несколько платных программ для внутренней оптимизации. Одна из таких программ – Screaming Frog. Рекомендуем!
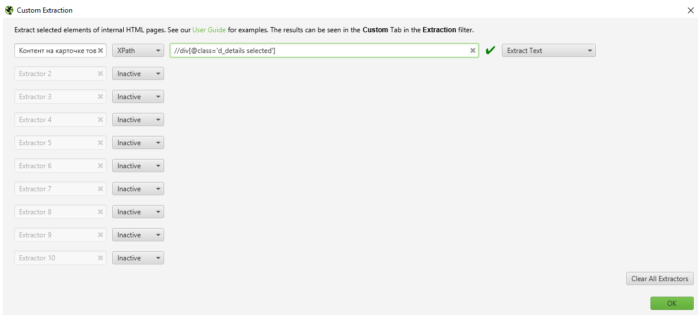
Программа может искать дубли в мета-тегах, заголовках h1-h2, а также имеет функцию парсинга html-элементов страницы через язык xpath, сss-селекторы и через регулярные выражения.
Как вариант можно попробовать использовать встроенные в поисковую систему возможности продвинутого поиска. Это имеет смысл, если исследуемый сайт не был добавлен в консоль для веб-мастеров и, соответственно, информация о нем недоступна. Шаблон для поиска выглядит так: site:домен intitle:”фраза для поиска”. В поисковую выдачу попадут все страницы из указанного сайта (в том числе, конечно же, и дубликаты), которые содержат искомую фразу.
Как не допустить дублирования контента
Как и в большинстве других ситуаций, лучше предотвратить появление проблемы, чем бороться с последствиями. Зная причины, по которым появляются дубликаты контента, можно предпринять соответствующие меры. Например:
- Не используйте идентификаторы сеансов в URL-адресах.
- Вместо отдельной страницы для печати, используйте динамически подключаемую таблицу стилей (CSS) для печати.
- Научитесь правильно закрывать пагинацию комментариев;
- Используйте скрипт, выстраивающий параметры в URL-адресах в предсказуемом, строго определенном порядке.
- Для отслеживания переходов используйте хэш, вместо параметров в URL-адресах.
Способы борьбы с дубликатами
Что делать, если дубликаты контента уже обнаружены на сайте? Существует несколько эффективных способов борьбы с этой проблемой:
- Перенаправление 301;
- Явное указание канонической страницы;
- Запрет на индексацию лишних ссылок.
Перенаправление 301
Одно из наиболее часто используемых решений для борьбы с дублирующимся контентом – это использование 301 перенаправления. Это постоянное перенаправление, которое обычно используется для того, чтобы помочь посетителям и поисковым системам найти страницу, которая была перемещена на новый URL-адрес.
Настройка переадресации с дублирующих страниц также позволит посетителям и поисковым системам определить страницу, которую следует считать основной. Тем самым поисковая система сможет корректно «склеить» дубликаты и проблема будет решена.
После редиректа нужно проследить за тем, чтобы в коде сайта не остались ссылки с кодом ответа 3**.
Явное указание канонической страницы
Атрибут «canonical» используется вместе с тэгом «link», чтобы сообщить поисковому роботу, какую из страниц считать основной (канонической).
Как и перенаправление 301, данный атрибут передает вес ссылок с дубликатов на основную страницу. Однако в отличие от перенаправления, тэг использовать проще. Недостаток – атрибут «canonical» не всегда решает проблему.
Запрет на индексацию лишних ссылок
Другой метатэг, который можно использовать для борьбы с дубликатами, это тэг «robots» с атрибутом «content=noindex, follow». В некоторых ситуациях этот тэг практически незаменим. Например, его очень удобно использовать для контента, который разбит на несколько страниц.