Дублі контенту на сайті: причини та рішення

Пошукова оптимізація передбачає цілу низку обов’язкових заходів щодо усунення помилок на сайті, що просувається. Один із таких кроків – виявлення та усунення дубльованого контенту. На подив, практично жоден сайт не обходиться без дублів. Причин тому безліч, але на кожну з них можна знайти адекватне рішення. Віктор Гуменюк, Team Lead відділу просування сайтів SEO-Studio, розповідає про дублі контенту.

Що таке дубльований контент і звідки він береться
Здавалося б, кожен матеріал на сайті розміщувався строго в єдиному екземплярі і зайвим копіям взятися просто нізвідки. Насправді механізм появи дублів не такий очевидний і тут є куди “копнути”.
Одній сторінці – одна унікальна URL-адреса. Справедливість такої вимоги підтверджує сама інтуїція, адже цілком природно, що веб-сторінка не може перебувати в різних місцях одночасно (за різними URL-адресами). Але якщо на зорі становлення інтернету ця вимога ще дотримувалася, то з появою динамічних сайтів і просунутих систем управління контентом (CMS) виявилося, що будь-яка сторінка може бути доступна за незліченною кількістю URL-адрес одночасно. Саме це і створює проблеми.
Коли пошукова система знаходить кілька URL-адрес, які ведуть на один і той самий контент, виникає дилема. Вважати ці адреси однією сторінкою чи різними? Особливо, якщо контент усе-таки трохи відрізняється, наприклад, допоміжними інформаційними блоками. І якщо потрібно ці сторінки “склеїти”, то який URL вважати основним?
Типові ситуації
Існує безліч ситуацій, які призводять до появи дубльованого контенту. Розглянемо найпоширеніші з них, які можна назвати типовими.
- Добавлення матеріалу до різних категорій. Якщо використовується так званий “людино-зрозумілий URL”, у якому зафіксовано категорію матеріалу, система управління контентом згенерує кілька URL’ів, по одному для кожної з категорій. У результаті з’явиться більше одного посилання на один і той самий матеріал (така проблема зустрічається вже досить рідко);
- Окрема сторінка для друку. Сторінка для друку відрізняється від основної сторінки тільки стилями оформлення. Але головне тут, що відмінності все-таки є, і пошукова система повинна буде вибрати URL для індексації та відображення в пошуковій видачі на свій розсуд (така проблема теж зустрічається рідко);
- Ідентифікатори сеансів. Для того щоб відстежувати відвідувачів на сайті, часто використовуються параметри в посиланні, які можуть містити безліч корисної інформації. Це призводить до того, що система генерує безліч унікальних посилань на одні й ті самі сторінки. Якщо відвідувач залишить де-небудь посилання зі своїм ідентифікатором сеансу, пошукова система це посилання знайде і тим самим виявить ще один зайвий дубль;
- Параметри сортування. Для відстеження параметрів сортування нерідко використовують той самий URL. Як і в попередньому прикладі, це призводить до створення дублів. Наприклад, товари можуть бути відсортовані за алфавітом, за датою додавання або за ціною. З огляду на URL без параметрів (сортування за замовчуванням), виникає вже 4 посилання на одну й ту саму сторінку;
- Пагінація для коментарів. Деякі CMS використовують пагінацію для коментарів, щоб розбити їх на кілька сторінок. При переході на іншу сторінку, основний контент зберігатиметься тим самим, але в посиланні з’явиться додатковий параметр. Причому цей параметр буде унікальним для кожної сторінки. Відповідно кожна така сторінка цілком справедливо може сприйматися як дублікат основного контенту з незначними змінами в коментарях;
- Домен с и без www. Типичная ситуация, когда домен доступен в двух вариантах сразу – с приставкой «www» и без нее. В последнее время появилась вариация этой проблемы, связанная с переходом на новый протокол. Страницы могут быть доступны в одно и то же время по протоколу «http» и «https»;
- Мимовільний порядок параметрів. Якщо сайт не використовує людино-зрозумілі URL’и, посилання на сторінки генеруються у вигляді набору параметрів “ключ=значення”. При цьому ці параметри можна довільно міняти місцями, що призводить до створення зайвих дублів.
Як перевірити сайт на дублі
Хороший спосіб перевірити сайт на наявність дублів, використовувати консоль для веб-майстрів Google. Після входу в систему, потрібно спочатку відкрити розділ “Вид у пошуку”, а потім – “Оптимізація HTML”. Тут можна побачити вичерпний список дублікатів, знайдених на сайті. Зрозуміло, для того щоб скористатися цим інструментом, знадобитися обліковий запис Google і підтвердження прав на сайт, який передбачається досліджувати.
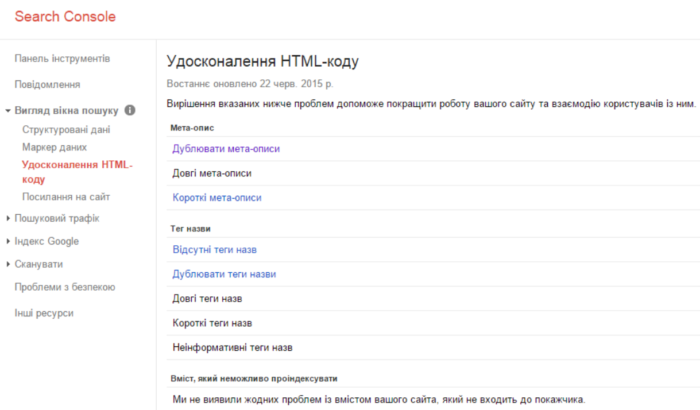
Але якщо ви тільки готуєте сайт і він закритий від індексації, за допомогою консолі для веб-майстрів Google ви не зможете знайти дублі. Ми в SEO-Studio використовуємо кілька платних програм для внутрішньої оптимізації. Одна з таких програм – Screaming Frog. Рекомендуємо!
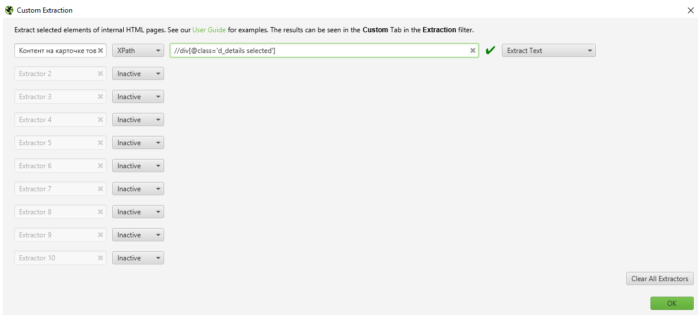
Програма може шукати дублі в мета-тегах, заголовках h1-h2, а також має функцію парсингу html-елементів сторінки через мову xpath, сss-селектори та через регулярні вирази;
Як варіант можна спробувати використовувати вбудовані в пошукову систему можливості просунутого пошуку. Це має сенс, якщо досліджуваний сайт не було додано в консоль для веб-майстрів і, відповідно, інформація про нього недоступна. Шаблон для пошуку має такий вигляд: site:домен intitle: “фраза для пошуку”. У пошукову видачу потраплять усі сторінки із зазначеного сайту (зокрема, звісно ж, і дублікати), які містять шукану фразу.
Як не допустити дублювання контенту
Як і в більшості інших ситуацій, краще запобігти появі проблеми, ніж боротися з наслідками. Знаючи причини, через які з’являються дублікати контенту, можна вжити відповідних заходів. Наприклад:
- Не використовуйте ідентифікатори сеансів в URL-адресах.
- Замість окремої сторінки для друку, використовуйте таблицю стилів (CSS) для друку, що динамічно підключається.
- Навчіться правильно закривати пагінацію коментарів;
- Використовуйте скрипт, що вибудовує параметри в URL-адресах у передбачуваному, строго визначеному порядку.
- Для відстеження переходів використовуйте хеш, замість параметрів в URL-адресах.
Способи боротьби з дублікатами
Що робити, якщо дублікати контенту вже виявлено на сайті? Існує кілька ефективних способів боротьби з цією проблемою:
- Перенаправлення 301;
- Явна вказівка канонічної сторінки;
- Заборона на індексацію зайвих посилань.
Перенаправлення 301
Одне з найбільш часто використовуваних рішень для боротьби з дубльованим контентом – це використання 301 перенаправлення. Це постійне перенаправлення, яке зазвичай використовується для того, щоб допомогти відвідувачам і пошуковим системам знайти сторінку, яку було переміщено на нову URL-адресу.
Налаштування переадресації з дублюючих сторінок також дасть змогу відвідувачам і пошуковим системам визначити сторінку, яку слід вважати основною. Тим самим пошукова система зможе коректно “склеїти” дублікати і проблему буде вирішено.
Після редиректу потрібно простежити за тим, щоб у коді сайту не залишилися посилання з кодом відповіді 3**.
Явна вказівка канонічної сторінки
Атрибут “canonical” використовується разом із тегом “link”, щоб повідомити пошуковому роботу, яку зі сторінок вважати основною (канонічною). Як і перенаправлення 301, цей атрибут передає вагу посилань із дублікатів на основну сторінку. Однак на відміну від перенаправлення, тег використовувати простіше. Недолік – атрибут “canonical” не завжди вирішує проблему;
Заборона на індексацію зайвих посилань
Інший метатег, який можна використовувати для боротьби з дублікатами, це тег “robots” з атрибутом “content=noindex, follow”. У деяких ситуаціях цей тег практично незамінний. Наприклад, його дуже зручно використовувати для контенту, який розбитий на кілька сторінок.